Step-by-Step Guide: Importing SQL Server Data into Databricks and Creating Dynamic Dashboard Visualizations
Author: Ryan Shiva
8 May, 2024

In today’s fast-paced business world, organizations are constantly seeking ways to harness the power of their data to drive insights and make informed decisions. SQL Server has long been a reliable workhorse for storing and managing data, but as data volumes grow and the need for real-time analytics intensifies, many are turning to more advanced platforms like Databricks. In this step-by-step guide, we’ll explore how Databricks can supercharge your data analytics capabilities, allowing you to seamlessly import data from SQL Server and create dynamic, interactive dashboard visualizations that bring your data to life.
Databricks offers a host of advantages over traditional SQL Server setups, from its ability to handle massive volumes of structured and unstructured data, to its powerful data processing and machine learning capabilities. With Databricks, you can easily create foreign catalogs to read external data without the need for ingestion and use CTAS statements to efficiently save data into optimized Delta tables. We’ll walk through an example using bike sales data, showing you how to leverage your Delta tables to power stunning dashboard visualizations that provide at-a-glance insights into your business performance.
Whether you’re a data analyst, business intelligence professional, or simply someone who wants to get more out of their data, this guide will equip you with the knowledge and skills you need to take your analytics to the next level with Databricks.
Benefits of Databricks Compared to SQL Server
Databricks and SQL Server are both powerful tools for managing and analyzing data, but Databricks has a number of key advantages over SQL Server. Let’s take a closer look at some of the benefits Databricks offers over traditional SQL Server setups:
- Scalability and Performance: One of the biggest advantages of Databricks is its ability to handle massive volumes of data with ease. Built on top of Apache Spark, Databricks can process data at lightning-fast speeds, making it ideal for big data workloads. SQL Server, on the other hand, can struggle with very large datasets and may require significant hardware investments to scale.
- Flexibility and Versatility: Databricks supports a wide range of data types and formats, including structured, semi-structured, and unstructured data. This makes it easy to work with data from diverse sources, such as log files, social media feeds, and IoT sensors. SQL Server is primarily designed for structured data and may require additional tools or workarounds to handle unstructured or semi-structured data effectively.
- Machine Learning and Advanced Analytics: Databricks comes with a host of built-in machine learning libraries and tools, making it easy to build and deploy sophisticated ML models directly within the platform. While SQL Server does offer some ML capabilities through Microsoft Machine Learning Services, Databricks provides a more comprehensive and user-friendly environment for data science and AI workloads.
- Collaborative Workspaces: Databricks includes collaborative workspaces that allow teams to work together seamlessly on shared projects. Users can create interactive notebooks, dashboards, and reports, and easily share them with colleagues for review and collaboration. While SQL Server does offer some collaboration features through tools like SQL Server Reporting Services, Databricks provides a more integrated and intuitive environment for team-based analytics.
- Cloud-Native Architecture: Databricks was designed from the ground up for the cloud, which means it can take full advantage of the scalability, flexibility, and cost-efficiency of cloud computing. While SQL Server can be deployed in the cloud, it may not be as well-suited to cloud-native architectures and may require more manual configuration and optimization.
Of course, SQL Server still has its place and may be the right choice for certain use cases, particularly those involving heavily transactional workloads or legacy systems. But for organizations looking to modernize their data analytics and take advantage of the latest advances in big data processing and machine learning, Databricks offers a compelling alternative that can help them stay ahead of the curve.
How to Create a Foreign Catalog to Read External Data into Databricks?
One of the most powerful features of Databricks is its ability to read external data without the need to ingest it into the platform. This is made possible through the use of foreign catalogs, which allow Databricks to query data stored in external systems like SQL Server. By creating a foreign catalog, data teams can:
- Access and analyze data from multiple sources in a single place
- Avoid the time and cost of data ingestion and duplication
- Ensure data consistency and freshness by querying the most up-to-date information
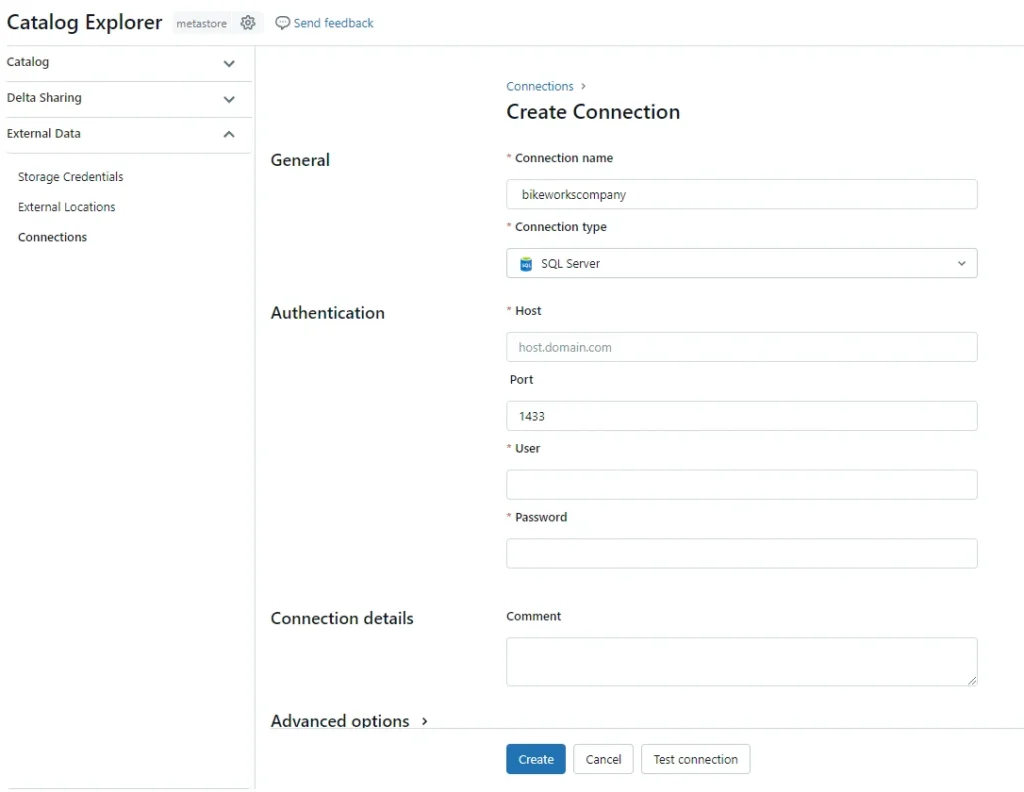
Creating a foreign catalog in Databricks is a straightforward process. First, users must define the external data source they wish to connect to, specifying details like the server name, database name, and authentication credentials. This can be done using the Databricks UI or through a SQL command.
Here, we will walk through the steps of setting up a foreign catalog to read bike sales data from SQL Server into Databricks:
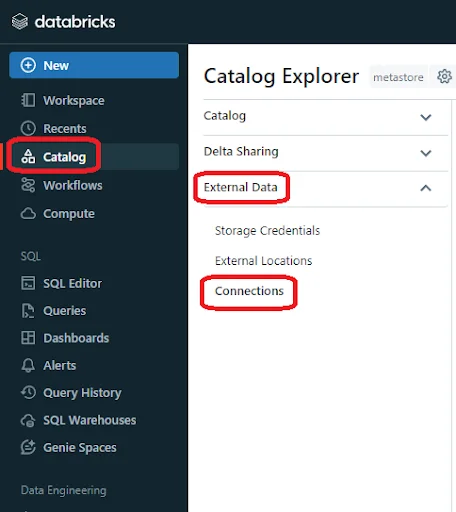
- In your Databricks workspace, navigate to “Catalog” -> “External Data” -> “Connections”.

- In the top right of the screen, click the “Create connection” button.
- Give the connection a name. Select “SQL Server” as the connection type. Fill in the authentication details to connect to your SQL Server database.
- Before you can connect to your SQL Server database, you may need to whitelist the IP Address of your cluster. This depends on the security configurations of your SQL Server database. Please contact us if you need any help with this configuration.
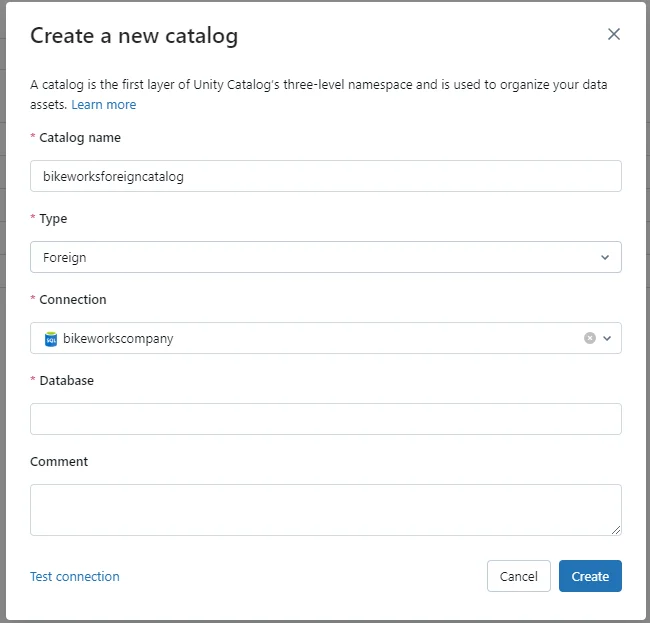
- Create the Foreign Catalog. Click “Catalog” in the navigation drawer and click the “Create Catalog” button.
- Fill in the catalog details. Give the catalog a name. For Type, select “Foreign”. Under Connection, select the connection you created in the previous step. Provide the Database name for your database in SQL Server.
That’s it! You now have a foreign catalog in Databricks which is configured to read data from your SQL Server database. You may query the catalog with SQL or Python the same way you would with a standard catalog stored in Databricks.
This approach offers significant benefits in terms of flexibility and efficiency. Rather than having to move large volumes of data into Databricks, users can leave the data where it is and simply query it as needed. This not only saves time and resources but also allows organizations to maintain a single source of truth for their data, reducing the risk of inconsistencies or errors.
Bike Sales Data Demo
The bike sales data we’ll be working on within this guide is a dataset that captures various aspects of a bike retailer’s sales operations. At its core, the data includes detailed information on each individual bike sale, such as the date of purchase, the model & category of the product, and the price paid by the customer. This granular, transaction-level data allows for the analysis of sales patterns and trends over time.
This information can help the retailer optimize their product mix, identify popular or slow-moving items, and ensure they have the right stock on hand to meet customer demand. By analyzing this product data alongside the sales and customer data, the retailer can make data-driven decisions to improve their overall business performance.
How to Use Tables in Databricks to Power Dashboard Visualizations?
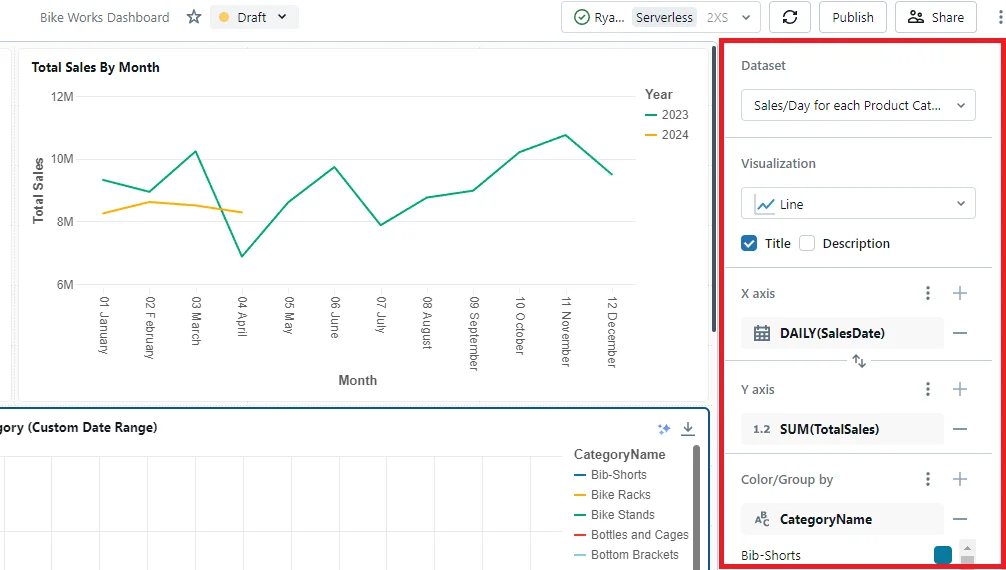
Now let’s dive into how we can use tables to power our dashboard visualizations in Databricks. Our aim is to use SQL Query to pull data and create some insightful visualizations. In our case, we are going to create two charts: one showing total sales per year and another showing daily sales for product categories.
To create a new Dashboard, navigate to “Dashboards” in the navigation Drawer and then click the “Create Dashboard” button.
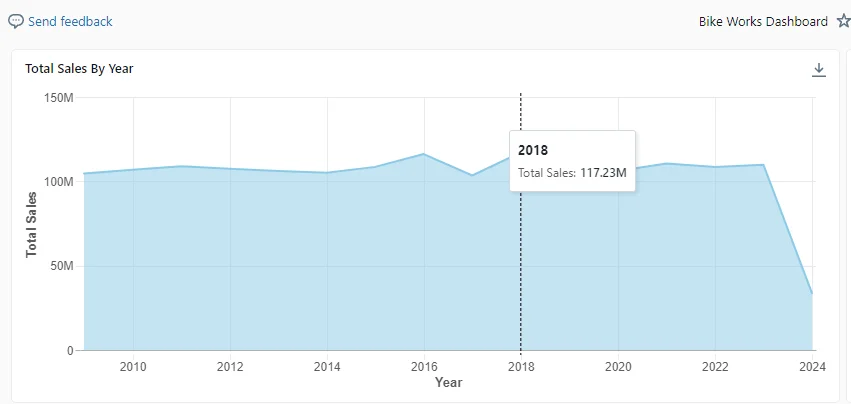
Total Sales by Year
The first chart is an “Area” type visualization that displays total sales for each calendar year. The X-axis represents the year, and the Y-axis represents the total sales for the year.
SELECT YEAR(soh.OrderDate) AS Year,
SUM(sod.LineTotal) AS TotalSales
FROM bikeworkscatalog.saleslt.salesorderheader soh
JOIN bikeworkscatalog.saleslt.salesorderdetail sod
ON soh.SalesOrderID = sod.SalesOrderID
GROUP BY YEAR(soh.OrderDate)
ORDER BY YEAR(soh.OrderDate); This query groups sales based on the year of the order date sums up the total sales for each group, and orders the result by year. In the Databricks dashboard, you simply need to set ‘Year’ as the X-axis and ‘SUM(TotalSales)’ as the Y-axis. Select the dataset you created from the SQL Query. Then, select ‘Area’ as the chart type to get a graphical representation of the total sales for each calendar year.
Sales/Day for Each Product Category
In the second chart, we focus on daily sales for each product category. This chart employs a date picker function that allows the user to select a date range for the order dates to display on the chart. This chart is a line graph where each line represents daily sales for a single category. The user can select which categories they want to be displayed on the chart by clicking one or more product categories listed to the right of the visualization. The X-axis represents the Date, and the Y-axis shows the Daily Sales.
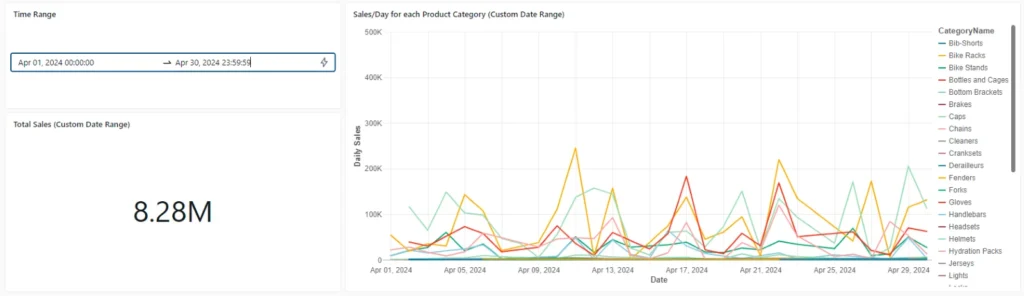
Below is the SQL Query for this visualization, configured to display data for the month of April 2024:
WITH SalesByDay AS (
SELECT pc.Name AS CategoryName,
DATE(soh.OrderDate) AS SalesDate,
SUM(sod.LineTotal) AS TotalSales
FROM bikeworkscatalog.saleslt.salesorderheader soh
JOIN bikeworkscatalog.saleslt.salesorderdetail sod ON soh.SalesOrderID = sod.SalesOrderID
JOIN bikeworkscatalog.saleslt.product p ON sod.ProductID = p.ProductID
JOIN bikeworkscatalog.saleslt.productcategory pc ON p.ProductCategoryID = pc.ProductCategoryID
GROUP BY pc.Name, DATE(soh.OrderDate)
)
SELECT CategoryName,
SalesDate,
SUM(TotalSales) AS TotalSales
FROM SalesByDay
GROUP BY CategoryName, SalesDate
ORDER BY SalesDate, CategoryName; This query first creates a temporary view of sales by each day and for each product category. It then groups these results by sales date and category, sums up the total sales for each group, and orders the output by sales date and category name.
On the Databricks dashboard, you’ll need to set ‘SalesDate’ as the X-axis and ‘SUM(TotalSales)’ as the Y-axis. Then, choose ‘Line’ as the chart type. To allow selection of the product category for the line chart, assign ‘CategoryName’ to “Color/Group by”.
Conclusion
We’ve seen how Databricks’ scalability, flexibility, and advanced analytics capabilities make it a compelling alternative to traditional SQL Server setups, particularly for organizations dealing with large volumes of diverse data. Through our example using bike sales data, we’ve demonstrated how you can use your data to create dynamic, interactive dashboards that provide valuable insights at a glance.
But perhaps most importantly, we’ve shown how Databricks can empower you to take control of your data and make better, more informed decisions for your business. Whether you’re a seasoned data professional or just starting out on your analytics journey, Databricks provides the tools and capabilities you need to succeed in today’s data-driven world.
So why wait? Start exploring the possibilities of Databricks today and discover how it can help you unlock the full potential of your data. With its intuitive interface, powerful processing capabilities, and rich ecosystem of tools and integrations, Databricks is the ultimate platform for anyone looking to take their analytics to the next level. Happy data wrangling!



