A Comparison of ML Capabilities on Snowflake and Databricks
Author: Ryan Shiva
23 October, 2024
Both Databricks and Snowflake allow users to securely and collaboratively build and deploy machine learning features, models, and applications. They share many features in common to facilitate the ML model lifecycle – Feature Store, Notebooks, Model Registry, and AI Assistants. New features are constantly being added, and it can be difficult to stay up to date on the latest additions of each platform.
In my experience, I’ve found that machine learning cloud platforms often offer tools that seem equivalent at first glance, but reveal significant limitations when examined more closely. That’s why I wanted to create a blog exploring the benefits and drawbacks I have encountered on both Databricks and Snowflake, focusing specifically on their capabilities in supporting ML workflows from development to production.
I am going to share an honest breakdown of how Databricks and Snowflake compare when it comes to ML use cases, going beyond the marketing fluff to provide a deeper understanding of how the tech stacks measure up to each other. From my experience, Databricks demonstrates superior performance and flexibility across a wider range of ML tasks. Its ability to develop and customize Compound AI systems, the built-in data governance and monitoring tools, and the cost-effective scaling for both training and inference give it an edge in handling complex, large-scale ML projects.
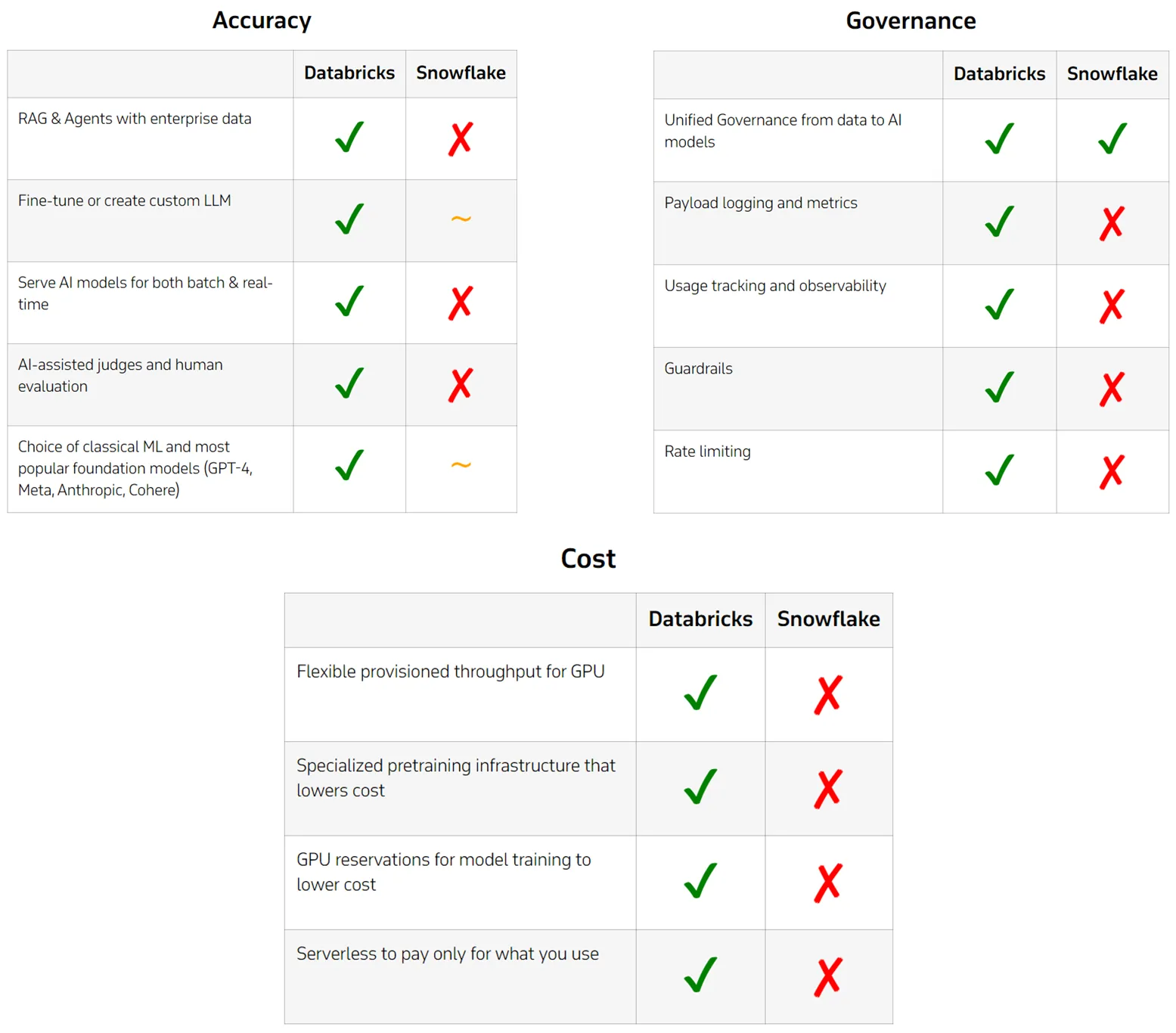
A comparison of ML Capabilities on Snowflake and Databricks
By the end of this blog, you’ll see why Databricks stands out as the more mature platform for productionalizing ML workflows, while Snowflake, despite its strengths in data warehousing, faces limitations that become apparent as machine learning needs evolve and scale.
ML Model Training
I will begin by comparing the AI tools available on Databricks and Snowflake for training ML models.
Snowpark ML Modeling
Snowflake offers Snowpark ML Modeling for feature engineering and ML training. Snowpark is a developer framework for Snowflake which is primarily used by Developers and Data Scientists, rather than Data Analysts. Like Databricks, Snowpark can run Python and other programming languages on enterprise data all in a single secure platform. The Snowpark ML Modeling library can be used to convert model training Python code into a Python Stored Procedure, which can then run on a Snowpark-optimized warehouse. Unfortunately, the stored procedure can only be run as a single-node ML training workload in Snowflake. This means that the model training cannot be distributed to save time on computationally intensive workloads, such as training neural networks.
Databricks ML Runtime
By contrast, Databricks offers infrastructure that is optimized for training ML models using distributed computation. Databricks Runtime ML has common ML libraries and tools pre-installed, and offers the option for GPU acceleration to speed up model training and inference. I have experienced firsthand how simple it is to execute model training in parallel on Databricks, leveraging a multi-node library such as Spark ML.
For example, here is some code which uses MLflow to train and log a Spark ML linear regression model:
with mlflow.start_run(run_name="LR-Single-Feature") as run:
# Define pipeline
vec_assembler = VectorAssembler(inputCols=["bedrooms"], outputCol="features")
lr = LinearRegression(featuresCol="features", labelCol="price")
pipeline = Pipeline(stages=[vec_assembler, lr])
pipeline_model = pipeline.fit(train_df)
# Log model
mlflow.spark.log_model(pipeline_model, "model", input_example=train_df.limit(5).toPandas())This Python code, which runs in a Databricks notebook, uses MLflow and the Spark ML library to train and log a machine learning model. To parallelize the workload, users don’t need to modify any code.
This code could easily be run and scaled to multiple nodes in Databricks simply by tuning the size of the cluster. The same workload would be impossible to parallelize in Snowpark. In fact, this model training code couldn’t even be run directly in Snowpark, since there is no exact mapping of code assets from Spark ML to Snowpark.
Delivering Production Quality GenAI
Now that we have been introduced to ML tooling on Snowflake and Databricks, I will evaluate the capabilities of each of the platforms to build and deliver production quality Generative AI implementations. The latest McKinsey Global Survey on AI shows that 65% of respondents say their companies are now regularly using generative AI in at least one area of their business. That’s almost double the share from last year, when only about one-third said the same. I have worked with customers to help them ask questions in English and generate quick answers and visualizations on their enterprise data. Another common GenAI application is developing a custom chatbot to automatically handle HR inquiries, saving costs and freeing up human resources for other tasks. To stay competitive, companies are looking for the platform that offers the most power and flexibility in implementing common GenAI use cases.
Compound AI systems
When it comes to building and deploying GenAI applications, I think that Databricks clearly beats out Snowflake in several key areas. Databricks provides a comprehensive ecosystem for developing Compound AI systems, allowing users to easily leverage enterprise data in RAG (Retrieval-Augmented Generation), Chains, Agents, fine-tuning, and fully custom models. This flexibility is crucial for businesses looking to tailor AI solutions to their specific needs. In contrast, Snowflake’s capabilities in this arena are significantly limited, lacking native support for building and hosting essential components like Chains and Agents.
retriever = chromadb_index.as_retriever()
hf_llm = HuggingFacePipeline.from_model_id(
model_id="google/flan-t5-large",
task="text2text-generation",
model_kwargs={"temperature": 0, "max_length": 128},
)
laptop_qa = RetrievalQA.from_chain_type(
llm=hf_llm, chain_type="stuff", retriever=retriever
)
laptop_name = laptop_qa.run("What is the full name of the laptop?") This Python code can be used in Databricks to set up a LLM Chain for querying documents for information about laptop reviews. This is a common technique in RAG applications – splitting the language interpretation and the document retrieval into multiple steps with separate models, improving the accuracy of the output.
Evaluation and monitoring of AI systems
Another critical aspect where Databricks has an advantage is in the evaluation and monitoring of AI systems. Databricks offers built-in metrics, AI-assisted judges, and human evaluation tools to help users understand Compound AI system quality. All payloads and metrics are logged alongside versions and parameters, enabling rapid iteration across the entire LLM lifecycle. This level of auditability and monitoring is essential for maintaining high-quality, safe AI systems in production. Snowflake, on the other hand, lacks native experiment management and model quality assessment capabilities, forcing users to rely on third-party solutions or build these critical components from scratch.
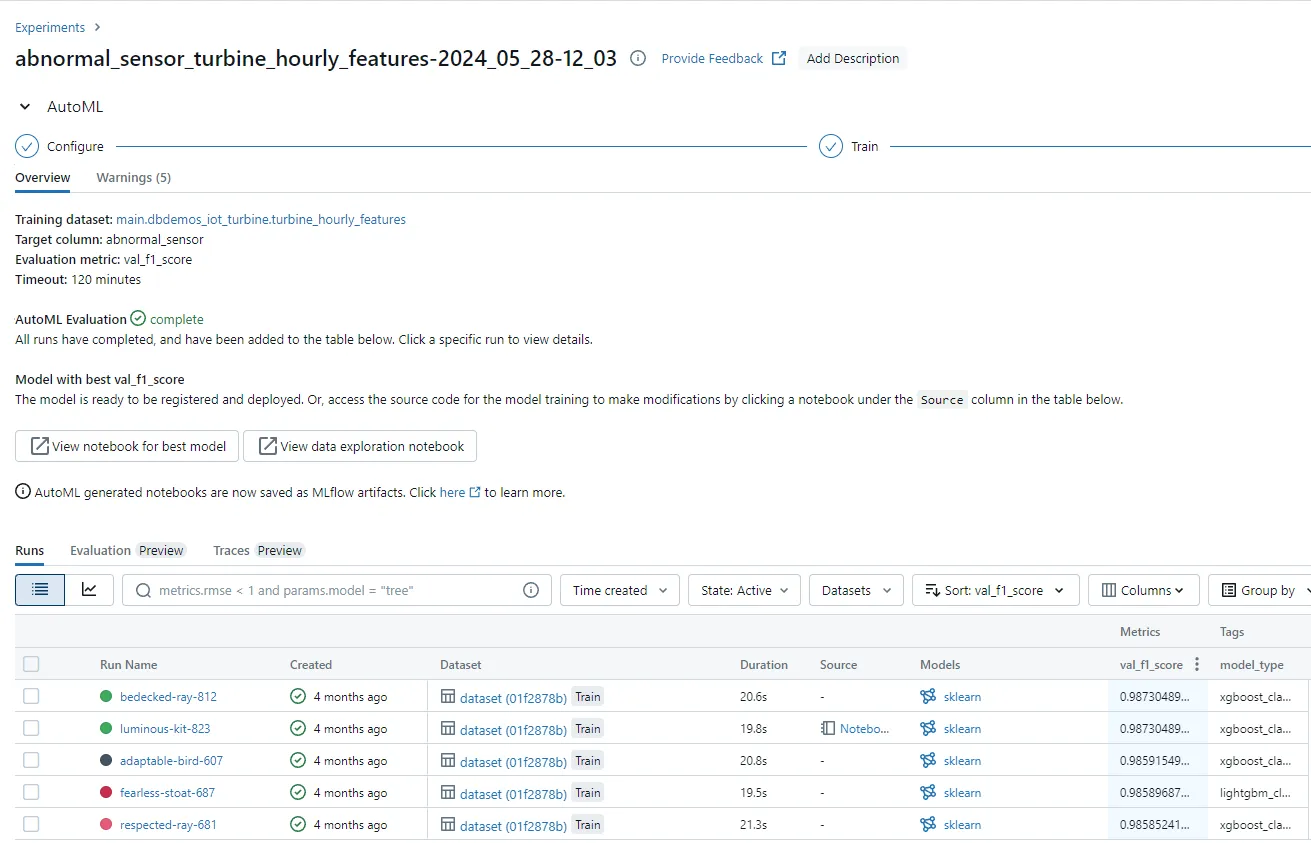
MLflow runs in Databricks are automatically organized into experiments. The Experiments UI makes it easy to track run metrics and find the best performing model at a glance.
TCO at Scale
When it comes to maintaining a low Total Cost of Ownership (TCO) at scale for machine learning and AI operations, Databricks offers significant advantages over Snowflake. This is particularly evident in the areas of model training and inference, where Databricks’ architecture and pricing model are designed to optimize cost-efficiency without compromising on performance.
Model Training Cost
For model training, Databricks leverages specialized ML/GenAI infrastructure that makes the process up to 10 times more cost-effective. Their serverless experience eliminates idle time costs, ensuring that users only pay for the training tokens consumed. Additionally, Databricks implements proprietary, research-driven training optimizations under the hood, further enhancing efficiency. In contrast, Snowflake relies on its data warehousing infrastructure for model training, which is not optimized for ML tasks. This leads to inefficiencies and higher costs, especially when users need to upsize their warehouse to meet memory constraints.
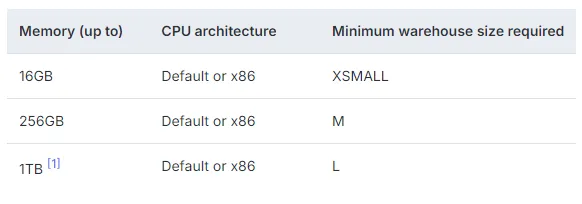
Configuration options for Snowpark-optimized warehouses. In Snowflake’s pricing model, increasing the memory forces the user to pay for a larger warehouse with more compute power, potentially leading to wasted resources.
Model Inference Cost
To understand the model inference costs on Databricks and Snowflake, you first need to know the difference between provisioned throughput and pay-per-token pricing strategies.
Provisioned throughput allows the user to submit a certain number of tokens at a time to a model-serving endpoint. On Databricks, these are dedicated endpoints that are scaled in terms of tokens per second, with a predictable cost per hour. Mosaic AI Foundation Model Serving on Databricks also offers a “scale to zero” option, which happens automatically after 30 minutes of no requests. This has a huge advantage over multi-tenant endpoints by reserving user-dedicated infrastructure to bring down latency and cost per token.
On the other hand, the price-per-token model charges a flat cost per 1,000 tokens used. The cost scales linearly with the amount of consumption and becomes extremely expensive with high rates of usage. Snowflake only offers multi-tenant endpoints with pay-per-token pricing, with no provisioned throughput capabilities. Even if you choose the price-per-token option in Databricks, Snowflake is three times more expensive than Databricks per input token for the latest OSS models (See Llama 3.1 405B Parameter Model Pricing Comparison).
Databricks also offers GPU reservations for model training, providing even lower pricing options for organizations with predictable workloads. For businesses looking to maximize their AI investments while keeping costs under control, Databricks presents a compelling case as the more cost-effective solution at scale.
Databricks: the Clear Choice for ML Workloads
Snowflake works fine for SQL analysts who simply need to apply pre-built models. However, it falls short for Data Scientists and ML Engineers for building and governing their own models. Companies that start using Snowflake might not realize these limitations until their ML use cases become more complex. By that point, their data is trapped in Snowflake’s proprietary format, with expensive fees to migrate to another platform.
It’s worth considering why a company would choose to lock users in with per-byte egress fees for data, rather than making their platform as open and integrated as possible, like Databricks. Personally, I prefer a platform that incentivizes users to stay by providing the most value, rather than resorting to vendor lock-in tactics. If you go to Snowflake looking for the most advanced, cost-effective ML capabilities, you may find yourself left out in the cold.
Partner with Xorbix Technologies for expert Databricks implementation and consulting services. Our certified experts will guide you through seamless implementation, migration, and optimization of your machine learning workflows.
- Schedule a free consultation
- Get a personalized Databricks roadmap
- Start your ML transformation journey
If you enjoyed this content and would like to see more, consider attending the next meeting of the Wisconsin Databricks User Group. Visit https://wisdbug.com/ to learn about our regular meetups where we share Databricks use cases, AI and machine learning features, and collaborate with users of all experience levels.



