Streamlining Data Administration with Databricks Unity Catalog
Author: Ryan Shiva
If your company uses Databricks, then you’ve probably heard of Unity Catalog. It’s the unified governance solution for the Lakehouse on Databricks, providing one central place to administer and audit your data. Databricks is distinguished from other cloud platforms in its ability to securely manage data and AI assets for all workspaces in an account. Unity Catalog is the foundation of Lakehouse on Databricks, which is the only truly unified Lakehouse platform with a governance solution spanning data, BI, and AI.
Why was Unity Catalog Created?
Traditionally, data and AI governance was complex and difficult to manage. Different personas, including data analysts, data engineers, and ML engineers needed varying levels of access to different sets of data. There were several platforms to manage as well – data lakes for unstructured data, data warehouses for structured data, and BI dashboards. As you can imagine, this resulted in a myriad of inefficiencies, complexities, and security risks. Duplicate tables were commonplace, making PII management and regulatory compliance a nightmare.
Challenges in Unity Catalog Adoption
Unity Catalog provides one governance model for all your unstructured and structured data, eliminating the complexity of setting up access control on multiple platforms for traditional data warehouses and data lakes. It allows users to access data more quickly and reduces human error. Over 10,000 Databricks customers have enabled Unity Catalog, recognizing that UC is the future of the Databricks platform. However, only 11.5% of all Databricks Units (DBUs) were tied to UC in 2023. Of the customers that have UC enabled, on average only 2.7% of their workspaces had UC enabled in 2023. The reason is that while it’s easy for new jobs to be created with Unity Catalog, it takes some work to migrate old jobs that are not UC enabled. The migration to Unity Catalog can be difficult, depending on the amount and complexity of the jobs and Lakehouse items. Copying a few tables from Hive Metastore to Unity Catalog will be much faster than migrating dozens of continuously streaming jobs and active clusters. The good news is that Databricks is currently hard at work simplifying and automating the migration process, step by step. Eventually, Databricks plans to fully automate the UC migration.
Whether you’re an experienced Databricks user with dozens of workspaces to migrate, or new to the platform and curious about how unified governance on Databricks can provide value for your organization, this blog post is for you. Unity Catalog is the future of the unified Lakehouse on Databricks, and by following these practices, your organization will be prepared to enjoy all the new UC dependent features Databricks will release in the coming years. The best practices outlined below will help you unlock the full potential of unified access control, data sharing, auditing, lineage, and monitoring on Databricks.
How to enable Unity Catalog
How to Check for Unity Catalog Enablement
Before you can start working with Unity Catalog, you should check whether your Databricks account has Unity Catalog enabled. This section will provide the steps to enable Unity Catalog in an Azure Databricks account.
How to check an Azure Databricks Account for Unity Catalog enablement:
- Use a Databricks admin account to log in to the account console.
- Navigate to “Workspaces”.
- Click the name of a workspace and check the “Metastore” section.
If there is a metastore name listed, then the workspace has Unity Catalog enabled.
How to Create a Unity Catalog Metastore
If there is no Unity Catalog metastore for your workspace’s region, a new one needs to be created. The metastore is the top-level container for all data objects secured by UC: tables, volumes, external locations, and more.
- Click on “Create Metastore” within the “Catalog” section.
- Enter a name for the metastore and select the region where the metastore will be deployed.
This should be the same region as your workspace.
Once the metastore is created, you will be able to add catalogs that will contain your tables, views, and other data items.
Best Practices for Unity Catalog enabled workspaces
To maximize the benefits of Unity Catalog within your workspaces, follow these best practices:
Keep track of data lineage for your Unity Catalog enabled Delta Live Pipelines
Delta Live Tables, a key component of Databricks’ unified Lakehouse platform, enhances data reliability and streamlines data engineering workflows. Databricks recommends using Unity Catalog with Delta Live Tables for most ETL workloads. One benefit of Delta Live Tables on Databricks is that DLT pipelines infer dependencies between the tables. All you need to do is define your tables in SQL or Python, and Delta Live Tables will automatically create or refresh the tables in the correct order when the pipeline is run. One important limitation to keep in mind is that a single DLT pipeline cannot write to both Unity Catalog and the Hive Metastore.
To write to Unity Catalog with Delta Live Tables, a new pipeline with UC enabled needs to be created. You will also need the CAN_VIEW permission on the pipeline to view the lineage. The creator of the pipeline has this permission assigned automatically when they create the pipeline. One the UC enabled pipeline is run, a user can view the upstream and downstream dependencies organized in a Directed Acyclic Graph (DAG) in the Catalog Explorer lineage UI.
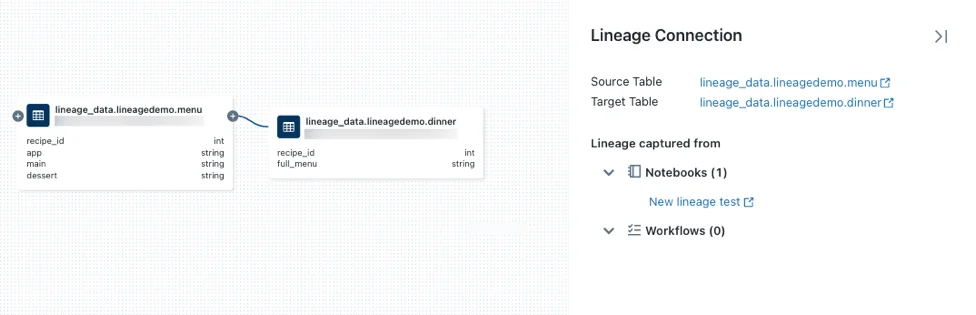
Lineage tracking allows you to verify the accuracy and quality of the data throughout the entire ETL (Extract, Transform, Load) process. You will be able to see the source of your data, who created it, when it was created, what transformations were performed, and more. You can reduce debugging time by easily tracing errors back to the downstream data source.
Implementing Data Masking and Row-Level Security in Unity Catalog
In addition to tracking data lineage, Unity Catalog facilitates data masking and row-level security on your tables. These features help you safeguard sensitive information and ensure controlled access to data. You can add masks to censor specific rows or columns that contain Personally Identifiable Information (PII) using fine-grained access controls.
Row filters allow you to apply filters to a table, ensuring that queries return only rows meeting specific criteria. For instance, you can create row filters based on user roles or specific conditions. Column masks, on the other hand, let you apply masking functions to table columns. These functions dynamically evaluate at query runtime, substituting the original column value with masked results based on user identity or other criteria. Conveniently, the logic for row filters and column masks gets added directly to the target table, without the need to create a new table or view (as is the case with dynamic views).
Let’s say you have a table employees that contains sensitive information, including the PII-containing column ssn. To enhance data privacy and limit access to these specific fields, you can implement a column mask within Unity Catalog. Here’s a straightforward code example in SQL syntax:
— Create a masking function for SSN column
CREATE FUNCTION ssn_mask(ssn STRING)
RETURN CASE WHEN IS_ACCOUNT_GROUP_MEMBER(‘admin’) OR IS_ACCOUNT_GROUP_MEMBER(‘human_resources’) THEN ssn ELSE ‘***-**-****’ END;
— Apply column masks to the ’employees’ table
ALTER TABLE employees ALTER COLUMN ssn SET MASK ssn_mask;
In this example, only members of the `admin` and `human_resources` groups would be able to view the employees’ Social Security numbers. For users that are not members of those groups, they would see ‘***-**-****’ in each cell for the ssn column when they select the table.
Connecting to External Locations with Unity Catalog on Databricks
At some point, you will likely need to import data into Databricks from an external location. Unity Catalog introduces a more secure approach to loading data from any cloud object storage location compared to using DBFS (Databricks File System). This section will outline the recommended practices for connecting to external locations and explain why it is advisable not to use DBFS in conjunction with Unity Catalog, unless you specifically need to access DBFS for migrating files into UC.
Before the introduction of Unity Catalog, data objects and access controls were scoped to the Hive Metastore within a single workspace, rather than across all workspaces in the account. The Hive Metastore utilized a two-namespace architecture for accessing data objects, as opposed to the three-namespace access employed by Unity Catalog. To access data in external locations using Hive Metastore, users could mount cloud object storage using data and storage credentials managed by DBFS. The DBFS was the root directory used as a default storage location for many workspace actions with Hive Metastore. DBFS is accessible to all users in a workspace, making it an inappropriate storage location for sensitive data. Any user in the workspace would be able to access the security credentials for the mounted storage. Unity Catalog, by contrast, manages tables with fine-grained ACLs to securely limit data access to certain users and groups. For this reason, Databricks recommends not to mount cloud object storage with DBFS.
The best way to access external cloud object storage is by creating an external location managed by Unity Catalog. First, you should create a storage credential using an IAM role to access the data in your cloud vendor account. Unity Catalog allows you to specify which users should have access to the credential. The recommended best practice is to use a cloud storage permission that has global privileges and then restrict access to the storage credential with Unity Catalog. Only Databricks account admins, metastore admins, or a user with the CREATE STORAGE CREDENTIAL privilege can create the storage credential.
For Azure Databricks accounts, you should create an `Azure Databricks access connector`, which is a first-party Azure resource used for connecting to your Azure Databricks account. Only Azure users with the role `Contributor` or higher can create the access connector. The access connector will have a `resource ID`. In the Catalog -> Storage Credentials section in Databricks, you have the option to “Add a storage credential”. To add the credential to Databricks, you should enter a name and enter the access connector’s resource ID.
Once the storage credential is saved in Unity Catalog, you will be ready to create your external location. You may run a command with the following syntax in a notebook or in the SQL query editor:
CREATE EXTERNAL LOCATION <location-name>
URL ‘abfss://<container-nathorame>@<storage-account>.dfs.core.windows.net/<path>’
WITH ([STORAGE] CREDENTIAL <storage-credential-name>);
You can also create the external location in Catalog Explorer. Refer to this documentation.
By following these practices, you will be able to benefit from a secure, unified data governance model on Databricks. There may be challenges in adopting Unity Catalog, but it’s well worth the effort to unlock the full potential of secure, unified, fine-grained access control for your Databricks Lakehouse.



