AI Testing and Evaluation Strategies
Author: Ammar Malik
Artificial Intelligence has become a prominent tool in today’s business practices and towards customer-facing applications. It has a variety of uses from maintaining IOT devices to simple chatbots, however, when developing this or making custom solutions it is important to ensure that the AI is functioning optimally. It can experience things like hallucinations where it is making up information rather than pulling it from the correct data source. In other applications, it is important to check the AI for any underlying bias or toxicity. Below we will discuss some of the metrics used to test AI to ensure that the content it is generating meets the standards of whatever application is being used for. Another interesting fact is in order to evaluate whether our answers are correct we would leverage another LLM to ensure the answers are correct. Libraries like DeepEval provide an easy way to test this, each metric is evaluated and gives reasons for either passing the unit tests or failing them.
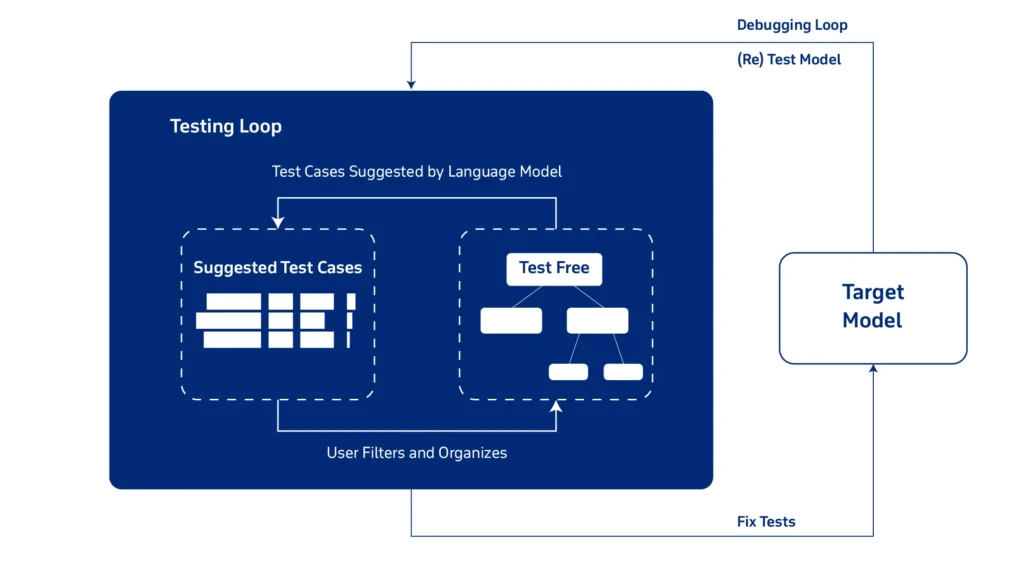
Test Cases
The testing engineer responsible for writing these unit tests must include prompts that everyday users will use and some edge cases to ensure that the LLM is highly adaptable to these changes. Furthermore, it must include what the expected output will be like. They must also include additional context to each prompt to ensure that the information being provided is not entirely made up, this is an essential part especially when the LLM is using a RAG pipeline to give its answers. One challenge the engineer might face is that writing these individual unit tests is very time-consuming and that time would take precious time away from further tuning the LLM. This is where testing datasets come into play.
Testing Datasets
As mentioned above, writing individual testing cases takes up a lot of time, so in order to mitigate this an engineer may use a synthesizer. A synthesizer has the ability to make up as many test cases as the engineer wants, boosting productivity. It leverages another LLM and still requires context to generate the testing prompts. Passing the context is a challenge that the engineer must solve as they must use different methods to get the document text and pass it to the synthesizer. After passing this context the LLM will make up prompts to be tested on and may use various different metrics to check if the LLM is providing the correct responses.
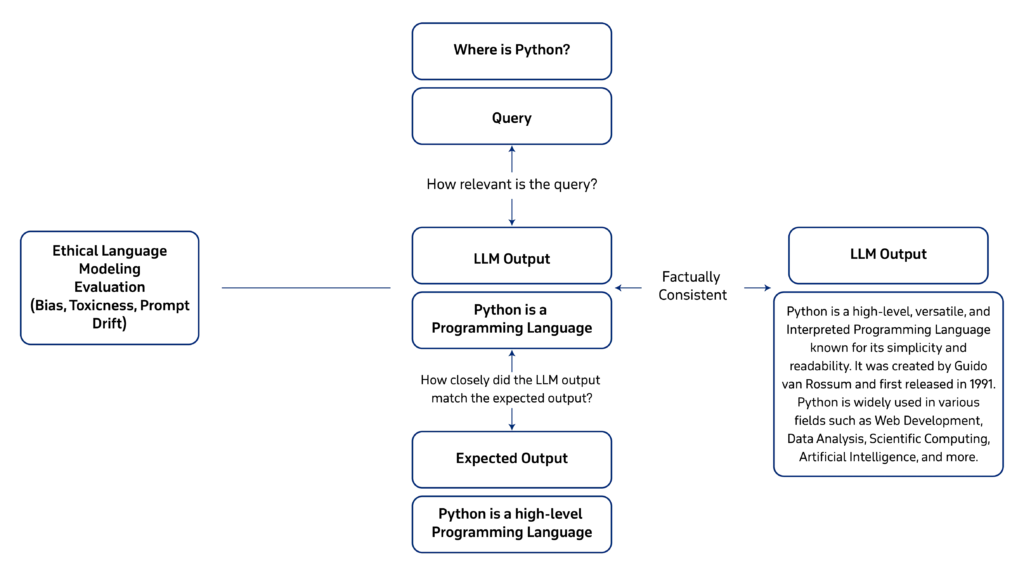
Metrics
Answer Relevancy
This is a common metric that evaluates whether the answer provided by the AI matches the input question. The testing LLM tokenizes the input prompt and compares it with the answer to check if the token count matches and exports the correct information.
Hallucination
This is another common metric that checks whether the answer provided by the LLM is from a data source and completely made up. Unlike the answer relevancy metric, this requires a retrieval context to ensure the answer matches the information in the context. After checking if the output contradicts what is in the retrieval context it returns the score accordingly.
Faithfulness
This metric is responsible for ensuring that the given answer matches the context it is being pulled from. It is an essential metric when your LLM is using a RAG pipeline as it measures how accurately the results match with the document text.
Contextual Relevancy, Precision, and Recall
Contextual relevancy, precision, and recall are very similar to the faithfulness metric but are more robust in detecting whether the information being provided by the LLM from the RAG pipeline and use different scoring metrics to detect any outliers.
Bias
This metric should only be used when making an LLM application that returns results that have answers concerning gender, racial, or political topics. In today’s world, it is important that each LLM provides answers without any bias and only reports answers based on factual information.
Toxicity
This metric evaluates whether the output answer is free from any toxic opinions. Testing AI for toxicity is crucial due to the potential risks associated with deploying AI systems. By evaluating AI models for toxicity prediction, we can ensure the reliability, accuracy, and ethical use of these systems.
Conclusion
In conclusion, the process of testing LLMs (Large Language Models) has revealed both the immense potential and the challenges associated with these advanced AI systems. Through rigorous evaluation and experimentation, researchers have uncovered the capabilities of LLMs in generating human-like text, assisting in various tasks, and advancing natural language understanding. However, this journey has also highlighted the importance of ethical considerations, bias mitigation, and robust evaluation frameworks to ensure responsible deployment and usage of LLMs. Looking to the future, testing LLMs will continue to be a critical area of research and development. By refining testing methodologies, addressing biases, enhancing interpretability, and fostering transparency in model behavior, we can harness the full power of LLMs while minimizing potential risks. Collaborative efforts among researchers, developers, policymakers, and ethicists will be essential in shaping the evolution of LLM testing practices.
Furthermore, as LLM technology advances and becomes more integrated into various applications, ongoing evaluation and validation will be paramount to maintain trust and reliability in these systems. Continuous monitoring, feedback loops, and adaptation strategies will be key components in ensuring that LLMs meet the evolving needs of users while upholding ethical standards and societal values.



